上一篇blog讲到了svm的原理,最后将需要解决问题抽象成了数学公式,但如何利用计算机,解出这些数学公式的答案。换句话说,就是怎么通过计算机算出我们的svm模型的参数呢?方法就是序列最小最优化(sequential minimal optimization, SMO)算法。
首先回顾一下SVM模型的数学表达,即svm的对偶问题:
\[ \begin{array}{l} \mathop {\min }\limits_a \qquad \frac{1}{2}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N { {a_i}{a_j}{y_i}{y_j}K({x_i},{x_j}) - \sum\limits_{i = 1}^N { {a_i}} } } \\ {\rm{s.t.}}\qquad\sum\limits_{i = 1}^N { {a_i}{y_i} = 0} \\ \qquad\qquad 0 \le {a_i} \le C, \qquad i = 1,2,\cdot\cdot\cdot,N \end{array} \]
选择一个 $ {a^*} $ 的正分量 $ 0 C $ , 计算(或者通过所有解求平均值):
\[ {b^*} = {y_j} - \sum\limits_{i = 1}^N {a_i^*{y_i}K({x_i} \cdot {x_j})} \]
决策函数为
\[ f(x) = sign(\sum\limits_{i=1}^N {a_i^*{y_i}K({x_i}, {x_j})} + {b^*}) \]
svm的学习,就是通过训练数据计算出\({a^*}\)和\({b^*}\),然后通过决策函数判定\({x_j}\)的分类。其中\({a^*}\)是一个向量,长度与训练数据的样本数相同,如果训练数据很大,那么这个向量会很长,不过绝大部分的分量值都是0,只有支持向量的对应的分量值大于0 。
SMO是一种启发式算法,其基本思想是:如果所有变量的解都满足了此最优化问题的KKT条件,那么这个最优化问题的解就得到了。否则,选择两个变量,固定其它变量,针对这两个变量构建一个二次规划问题,然后关于这个二次规划的问题的解就更接近原始的二次归还问题的解,因为这个解使得需要优化的问题的函数值更小。
翻译一下:对于svm我们要求解\({a^\*}\),如果 \({a^\*}\) 的所有分量满足svm对偶问题的KKT条件,那么这个问题的解就求出来了,我们svm模型学习也就完成了。如果没有满足KKT,那么我们就在 \({a^\*}\) 中找两个分量 \({a_i}\) 和 \({a_j}\),其中 \({a_i}\) 是违反KKT条件最严重的分量,通过计算,使得 \({a_i}\) 和 \({a_j}\) 满足KKT条件,直到\({a^\*}\) 的所有分量都满足KKT条件。而且这个计算过程是收敛的,因为每次计算出来的新的两个分量,使得对偶问题中要优化的目标函数(就是min对应的那个函数)值更小。至于为什么是收敛的,是因为,每次求解的那两个分量,是要优化问题在这两个分量上的极小值,所以每一次优化,都会使目标函数比上一次的优化结果的值变小。
我们来看看KKT条件。
KKT
上面的问题,是通过svm的原始问题,构造拉格朗日函数,并通过对偶换算得出的对偶问题。与对偶问题等价的是对偶问题的KKT条件,参考《统计学习方法》的附录C的定理C.3。换句话说,就是只要找到对应的\({a^\*}\)满足了下列KKT条件,那么原始问题和对偶问题就解决了。
SVM的对偶问题对应的KKT条件为:
\[ \begin{array}{l} \quad {a_i} = 0 \quad \Leftrightarrow \quad {y_i}g({x_i}) \ge 1\\ 0 < {a_i} < C \quad \Leftrightarrow \quad {y_i}g({x_i}) = 1\\ \quad {a_i} = C \quad \Leftrightarrow \quad {y_i}g({x_i}) \le 1 \end{array} \]
其中:
\[ g(x) = \sum\limits_{i = 1}^N { {a_i}{y_i}K({x_i},{x_j}) + b} \]
因为计算机在计算的时候是有精度范围的,所以我们引入一个计算精度值\(\varepsilon\),
\[ \left\{ \begin{array}{l} {a_i} = 0 \Leftrightarrow {y_i}g({x_i}) \ge 1 - \varepsilon \\ 0 < {a_i} < C \Leftrightarrow 1 - \varepsilon \le {y_i}g({x_i}) \le 1 + \varepsilon \\ {a_i} = C \Leftrightarrow {y_i}g({x_i}) \le 1 + \varepsilon \end{array} \right\} \Rightarrow \left\{ \begin{array}{l} {a_i} < C \Leftrightarrow 1 - \varepsilon \le {y_i}g({x_i})\\ 0 < {a_i} \Leftrightarrow {y_i}g({x_i}) \le 1 + \varepsilon \end{array} \right\} \]
同时由于\({y_i} = \pm 1\),所以\({y_i}\*{y_i}=1\),上面的公式可以换算为
\[ \begin{array}{l} {a_i} < C \Leftrightarrow - \varepsilon \le {y_i}(g({x_i}) - {y_i})\\ 0 < {a_i} \Leftrightarrow {y_i}(g({x_i}) - {y_i}) \le + \varepsilon \end{array} \]
定义:
\[ {E_i} = g({x_i}) - {y_i} \]
其中,\(g({x})\)其实就是决策函数,所以\({E_i}\)可以认为是对输入的\({x_i}\)的预测值与真实输出\({y_i}\)之差。
上面的公式就可以换算为,即KKT条件可以表示为:
\[ \begin{array}{l} {a_i} < C \Leftrightarrow - \varepsilon \le {y_i}{E_i}\\ 0 < {a_i} \Leftrightarrow {y_i}{E_i} \le + \varepsilon \end{array} \]
那么相应的违规KKT条件的分量应该满足下列不等式:
\[ {\rm{Against\ KKT:}} \]
\[ \begin{array}{l} {a_i} < C \quad \Leftrightarrow \quad - \varepsilon > {y_i}{E_i}\\ 0 < {a_i} \quad \Leftrightarrow \quad {y_i}{E_i} > + \varepsilon \end{array} \]
其实上面的推导过程不必关心,只需要应用违犯KKT条件的公式就可以了。
SMO算法描述
输入:训练数据集 $ T=\{({x_1},{y_1}),({x_2},{y_2}), ,({x_N},{y_N})\} $
其中$ {x_i} \(,\){y_i} \{-1,+1\}\(,\)i=1,2,,N\(,精度\)$。
输出:近似解\(\hat a\)
算法描述:
取初始值\({a^{(0)}}=0\),令\(K=0\)
选取优化变量 \({a\_1^{(k)}}\) , \({a\_2^{(k)}}\) , 针对优化问题,求得最优解 \({a\_1^{(k+1)}}\) , \({a\_2^{(k+1)}}\) 更新 \({a^{(k)}}\) 为 \({a^{(k+1)}}\) 。
在精度条件范围内是否满足停机条件,即是否有变量违反KKT条件,如果违反了,则令\(k=k+1\),跳转(2),否则(4)。
求得近似解\(\hat a = a^{(k+1)}\)
上面算法的(1)、(3)、(4)步都不难理解,其中第(3)步中,是否违反KKT条件,对于\(a^{(k)}\)的每个分量按照上一节的违反KKT条件的公式进行验算即可。难于理解的是第(2)步,下面就重点解释优化变量选取和如何更新选取变量。
变量选取
变量选取分为两步,第一步是选取违反KKT条件最严重的\({a\_i}\),第二步是根据已经选取的第一个变量,选择优化程度最大的第二个变量。
违反KKT条件最严重的变量可以按照这样的规则选取,首先看\(0 \lt {a\_i} \lt C\)的那些分量中,是否有违反KKT条件的,如果有,则选取\({y\_i}g({x\_i})\)最小的那个做为\({a\_1}\)。如果没有则遍历所有的样本点,在违反KKT条件的分量中选取\({y\_i}g({x\_i})\)最小的做为\({a\_1}\)。
当选择了\({a\_1}\)后,如果\({a\_1}\)对应的\(E\_1\)为正,选择\(E\_i\)最小的那个分量最为\({a\_2}\),如果\(E\_1\)为负,选择\(E\_i\)最大的那个分量最为\({a\_2}\),这是因为\({a\_2^{new}}\)依赖于\(\left| {E\_1 - E\_2} \right|\)(后面的公式会讲到)。 如果选择的\({a\_2}\),不能满足下降的最小步长,那么就遍历所有的支持向量点做为\({a\_2}\)进行试用,如果仍然都不能满足下降的最小步长,那么就遍历所有的样本点做为\({a\_2}\)试用。如果还算是不能满足下降的最小步长,那么就重新选择\({a\_1}\)。
计算选取变量的新值
首先计算出来的新值必须满足约束条件\(\sum\limits\_{i = 1}^N { {a\_i}{y\_i} = 0}\) ,那么求出来的\({a\_2^{new}}\)需要满足下列条件(具体推导见《统计学习方法》的7.4.1):
\[ \begin{array}{l} L \le a_2^{new} \le H\\ L = \max (0,a_2^{old} - a_1^{old}),H = \min (C,C + a_2^{old} - a_1^{old}), \qquad {y_1} \ne {y_2}\\ L = \max (0,a_2^{old} + a_1^{old} - C),H = \min (C,a_2^{old} + a_1^{old}), \qquad {y_1} = {y_2} \end{array} \]
未经过裁剪的\({a\_2}\)的解为:
\[ \begin{array}{l} {a_2^{new,unc}} = {a_2^{old}} + \frac{ {y_2}({E_1}-{E_2)}}{\eta} \\ \eta = K_{11} + K_{22} - 2{K_{12}} \end{array} \]
裁剪后的解为
\[ a_2^{new} = \left\{ \begin{array}{l} H,a_2^{new,unc} > H\\ a_2^{new,unc},L \le a_2^{new,unc} \le H\\ L,a_2^{new,unc} < L \end{array} \right. \]
第一个变量的解为
\[ a_1^{new} = a_1^{old} + {y_1}{y_2}(a_2^{old} - a_2^{new}) \]
还需要更新\(b\):
\[ \begin{array}{l} b_1^{new} = - {E_1} - {y_1}{K_{11}}(a_1^{new} - a_1^{old}) - {y_2}{K_{21}}(a_2^{new} - a_2^{old}) + {b^{old}}\\ b_2^{new} = - {E_2} - {y_1}{K_{12}}(a_1^{new} - a_1^{old}) - {y_2}{K_{22}}(a_2^{new} - a_2^{old}) + {b^{old}} \end{array} \]
在更新\(b\)时,如果有\(0 \lt a\_1^{new} \lt C\), 则\(b^{new}=b\_1^{new}\),如果有\(0 \lt a\_2^{new} \lt C\), 则 \(b^{new}=b\_2^{new}\), 否则\(b^{new}=\frac{b\_1^{new} + b\_2^{new}}{2}\)。
由于缓存了\({E\_i}\),所以需要计算新的\({E\_i}\):
\[ E_i^{new} = \sum\limits_{j=1}^N { {y_j}{a_j}K({x_i},{x_j})} + b^{new} - y_i \]
SMO的一个实现例子
我实现了一个简单的基于SMO的线性svm,是一个python脚本。实现的过程中,变量的选取并未严格按照算法讲的方法选取,选择了一个简单的选取方法。 一次迭代中,遍历所有的\({a\_i}\),如果\({a\_i}\)违反了KKT条件,那么就将它做为第一个变量,然后再遍历所有的\({a\_i}\),依次做为第二个变量,如果第二个变量有足够的下降,那么就更新两个变量。如果没有,就不更新。
实现的python脚本如下:
1 | #!/usr/bin/env python |
脚本使用的训练数据可以下载SMO实现的代码的svm.train文件,或者使用blog_linear.py,通过改变变量separable可以生成能够完全划分开的样本和不能划分开的样本。
这个smo.py脚本是一个线性的svm,替换掉脚本中kernel函数,就可以成为一个非线性的svm。 下面这两张图片是用训练数据训练的结果。这一张是样本能完全分离开的:
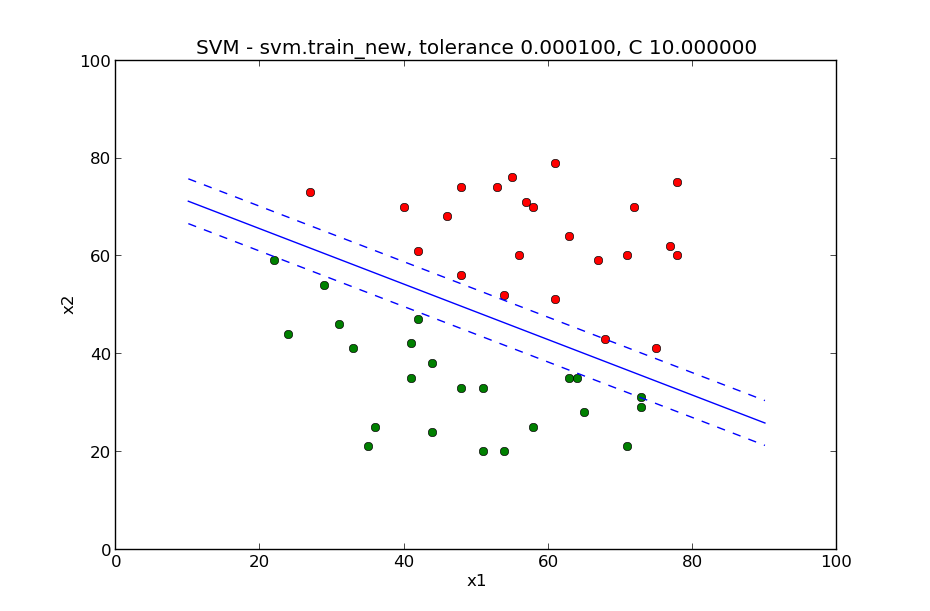
这一张是样本不能完全分离开的:
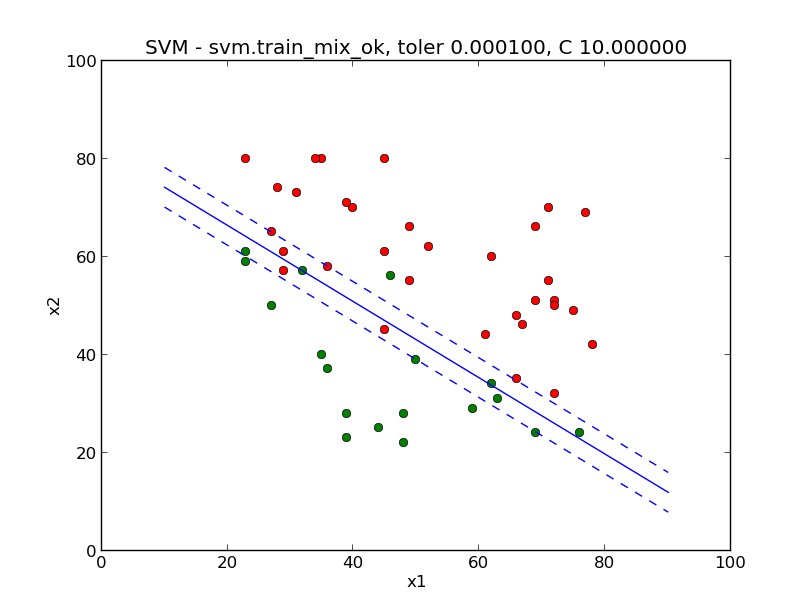
以上就是如何实现SMO的全部内容。之前的一个同事实现了一个简单的识别手写数字ocr,下一章,我们也来用svm实现一个简单的识别数字的ocr吧。