是今年工作中才开始接触机器学习的,之前有所听说,但是也没有深入了解过。其实所谓的接触主要是照着李航的这本《统计学习方法》学习。当时我们是几个同事每人学习一章,学完了,然后给大家办个讲座。我想既然学习了,就应该写博客把这些内容记录下来。于是,就开始写了。
机器学习是最近十年兴起的一门学科。人工智能是计算机学界的一个公认的难题,而机器学习被认为是最有可能解决这个难题的一门学科。当然机器学习在其它很多领域都有应用,比如数据挖掘,信息检索,语言识别,图像识别等很多领域。对于机器学习的基本概念,可以看《统计学习方法》的第一章,发展历史可以看wikipedia的Machine learning。我这里就不罗嗦了。等以后再写一篇机器学习的综述文章吧。
按照《统计学习方法》的划分,机器学习可以分为监督学习,无监督学习和半监督学习、强化学习等。该书讲了监督学习,总共讲了这些学习模型:感知机、k近邻法、朴素贝叶斯法、决策树、逻辑斯谛回归、最大熵、支持向量机、EM算法、隐马尔科夫模型、条件随机场。我先把我们学习过的模型写成博客吧。但其实每个模型都有很多内容,以我一个初学者的水平估计也讲不了什么,我就按照我的理解讲,每个模型争取能实现一个例子,供大家参考。
今天第一篇,SVM(support vector machine, 支持向量机)。
线性支持向量机
SVM是一个分类器,而且还只能二分,也就是回答yes or no的问题。先用图说话,

上面的图中的红点和绿点分布代表不同的两个类别,很明显了可以用一条直线将它们分开, 例如下面的蓝线。

上面的蓝线就是一种分类方法,当然你也可以画一条曲线,或者用一个圆圈把红点包围起来,这些都可以。用一条直线划分,就是线性的划分方式。这样的线性划分方式,可以用感知机,也可以用线性支持向量进行划分。(关于感知机,可以参考《统计学习方法》的第二章,这里就不多讲了。
其实这样的直线有很多条,例如下图中的蓝线、红线、黄线,都是可以。

那么svm是按照什么原则确定哪条划分的直线呢?svm的原则是“找到一条直线,把所有的样本点尽量分开”,换句话说,在一类样本点中,离划分直线最近点,到划分直接的距离要越大越好,那些点就被称之为支撑向量(surpport vector)。支持向量机的学习目标,就是找到那样的一条划分直线。例如下图中的蓝色实线,就是一个支持向量机。

图中在蓝色虚线上的3个点,就是支持向量。现在来理解一下“距离越大越好”,这个距离是指的支持向量到划分直线的距离,对应图中的粉色线条,并不是说的两个支持向量直接的距离,即非图中的绿色线条。
以上就是一个简单的svm的原理模型。稍微扩展一下,上面的例子中,所有的点都是二维的,那么就可以用一条直线把它们划分开,对于样本点是多维的情况,那么支持向量机算出来的是一个超平面,也称之为间隔分离超平面。
可以将上面的问题,抽象化,即最大化间隔分离超平面,可以用下面的公式表示(推导见《统计学习方法》的7.1):
\[ \begin{array}{l} \mathop {\max }\limits_{w,b} \qquad \frac{\hat \gamma }{\left\| w \right\|}\\ {\rm{s.t.}} \qquad {y_i}(w\cdot{x_i} + b) \ge \hat \gamma \end{array} \]
上面的公式中,\(\hat \gamma\)表示样本点到分离超平面的距离,\({x_i}\)为样本点,\({y_i}\)为样本点的分类,这里一般取1和-1。
可以令\(\hat \gamma = 1\),另最大化\(\frac{1}{\left \\| w \right \\|}\)与最小化\(\frac{1}{2}\left\\| w \right\\|^2\)是等价的,所以上面的公式可以变化为:
\[ \begin{array}{l} \mathop {\max }\limits_{w,b} \qquad \frac{1}{2}\left\| w \right\|^2\\ {\rm{s.t.}} \qquad {y_i}(w\cdot{x_i} + b) - 1 \ge 0 \end{array} \]
求解上面的问题,可以通过建立拉格朗日函数,并通过对偶变化,最终将问题转换成求解下面的公式:
\[ \begin{array}{l} \mathop {\min }\limits_a \qquad \frac{1}{2}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N { {a_i}{a_j}{y_i}{y_j}({x_i}\cdot{x_j}) - \sum\limits_{i = 1}^N { {a_i}} } } \\ {\rm{s.t.}}\qquad\sum\limits_{i = 1}^N { {a_i}{y_i} = 0} \\ \qquad\qquad{a_i} \ge 0, \qquad i = 1,2,\cdot\cdot\cdot,N \end{array} \]
上面式子中的\({a_i}\)为拉格朗日因子, \(N\)为样本的数量。svm的学习实际上就是求出分离超平面,也就是求解上面公式中的\({a_i}\)。假设上面问题的解为
\[ {a^*} = {\left( {a_1^*,a_2^*, \cdot \cdot \cdot ,a_N^* } \right)^T} \]
同时存在下标\(j\)使得 $ a_j^* 0 $ ,那么分离超平面的解为:
\[ \begin{array}{l} {w^*} = \sum\limits_{i = 1}^N {a_i^*{y_i}{x_i}} \\ {b^*} = {y_j} - \sum\limits_{i = 1}^N {a_i^*{y_i}({x_i} \cdot {x_j})} \end{array} \]
分离超平面可以表示为
\[ \sum\limits_{i=1}^N {a_i^*{y_i}({x_i} \cdot {x_j})} + {b^*} = 0 \]
分类的决策函数可以写成
\[ f(x) = sign(\sum\limits_{i=1}^N {a_i^*{y_i}({x_i} \cdot {x_j})} + {b^*}) \]
\(sign\)为符号函数,如果函数类的表达式算出来的值为正,符号函数的结果为1,对应分类的正样本,反之,符号函数的结果为-1,对应分类的负样本。
软间隔最大化
对于上面的例子,可以用一条直线或者说一个超平面将训练集分开,但往往问题没有那么简单。绝大多数的情况下两类样本是无法完全分来的。虽然绝大部分的点可以分开,但是还是有少部分点混合在一起无法分开。

上图的例子就是这样的一个例子了。无论怎么画直线都不可能把两类点完全分开。但如果我们可以容忍一部分点出现异常,或者不完全满足大于等于1的条件,那么就可以对每个样本点引入一个松弛变量\({\xi _i} \gt 0\), 同时为目标函数需要为每个\({\xi _i}\)付出代价,这样线性svm的目标函数就变成了这样(原始问题)
\[ \begin{array}{l} \mathop {\max }\limits_{w,b,\xi } \qquad \frac{1}{2}{\left\| w \right\|^2} + C\sum\limits_{i = 1}^N { {\xi _i}} \\ {\rm{s.t.}} \qquad {y_i}(w \cdot {x_i} + b) \ge 1 - {\xi _i}, \qquad i = 1,2, \cdot \cdot \cdot ,N\\ \qquad \qquad {\xi _i} \ge 0, \qquad i = 1,2, \cdot \cdot \cdot ,N \end{array} \]
上式中的\(C \gt 0\)称为惩罚参数,由应用问题决定,通常也是模型调优时,需要重点关注的参数。\(C\)值大,对误分类的惩罚增大,值小,对误分类的惩罚减小。
这样原始问题的对偶问题就变成了这样(参考《统计学习方法》的7.2):
\[ \begin{array}{l} \mathop {\min }\limits_a \qquad \frac{1}{2}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N { {a_i}{a_j}{y_i}{y_j}({x_i}\cdot{x_j}) - \sum\limits_{i = 1}^N { {a_i}} } } \\ {\rm{s.t.}}\qquad\sum\limits_{i = 1}^N { {a_i}{y_i} = 0} \\ \qquad\qquad 0 \le {a_i} \le C, \qquad i = 1,2,\cdot\cdot\cdot,N \end{array} \]
引入松弛变量的对偶问题,与没有引入的对偶问题的差别很小,仅仅是拉格朗日因子\({a_i}\)的取值范围不同,没有引入松弛变量的为\({a_i} \ge 0\), 引入的为\(0 \le {a_i} \le C\), 松弛变量在数学变换中,被消除了。
上面对偶问题求出的解和分离超平面、分类决策函数与之前求出的表达式是一直的。唯一不同的是下面的求 \({b^\*}\) 表达式
\[ {b^*} = {y_j} - \sum\limits_{i = 1}^N {a_i^*{y_i}({x_i} \cdot {x_j})} \]
原来寻找下标j的条件为 \(a_j^\* \gt 0\), 现在变为了 \(0 \lt a_j^\* \lt C\)
由于引入松弛变量后的对偶问题的解有可能不能满足上面的条件,所有的解都等于\(C\),计算时可以取所有解计算出来的均值,即将所有解对样的样本点带入上面求 \({b^\*}\) 的公式中,计算出 \({b^\*}\) 后,再求均值。
对于上面对偶问题的解,如果 \({a^\*} \gt 0\), 那么这样的解对应的样本点\({x_i}\),都称之为支持向量(软间隔的支持向量),样本点\({x_i}\)到间隔边界的距离为\(\frac{\xi _i}{\left \\| w \right \\|}\)。可以参考《统计学习方法》的图7.5。
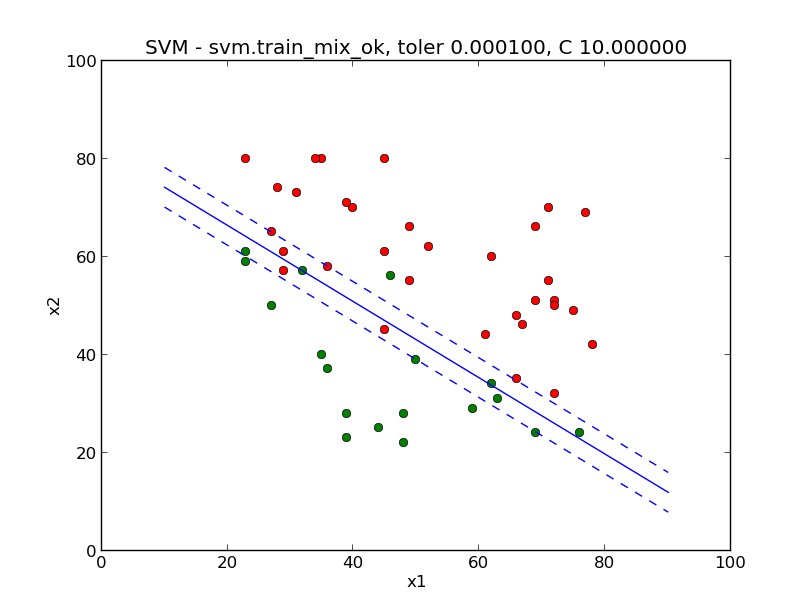
下面是根据上面的例子计算出来的分离直线和间隔边界
非线性支持向量机
上面讲到了线性支持向量机,但实际情况中,还有很多更混杂在一起的数据,不能用线性支持向量机,但是还可以用非线性支持向量机。看下面的一个例子。

上图中,左边的图中的点是无法用线性函数分开的,但是非线性可以划分开,例如用一个圆可以划分开。还有一种方法,经过一定的数学映射后,数据就变得可以线性划分了。例如上图中的右图,考虑使用下面的映射后,就可以用图中的蓝线划分开,当然也就可以应用svm了。
\[ ({x_1},{x_2}) \to (x_1^2,x_2^2) \]
非线性支持向量机,就是利用了和上面方法相同的思路,解决线性不可分的问题。这个方法叫核函数。
设$\(是输入空间,规定了一个映射函数\)(x)\(,如果对于所有的\)x,z \(,核函数\)K(x,z)$都满足
\[ K(x,z) = \phi (x) \cdot \phi (z) \]
其中\(\phi (x) \cdot \phi (z)\)为内积。
有了核函数,就可以讲数据\(x_i\)映射到更高的维度,甚至是无穷维,但同时又满足了内积的约束,就可以使用SVM去解决这个问题。可以参考《统计学习方法》的例子7.3,这个例子就实现了将\(x\)映射到高纬度, 并满足核函数的定义。
那么核函数是怎么用到svm中的呢?实际上就是替换对偶问题中的最小化的目标函数,将
\[ \mathop {\min }\limits_a \qquad \frac{1}{2}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N { {a_i}{a_j}{y_i}{y_j}({x_i}\cdot{x_j}) - \sum\limits_{i = 1}^N { {a_i}} } } \]
用核函数替换\({x_i}\cdot{x_j}\),变成
\[ \mathop {\min }\limits_a \qquad \frac{1}{2}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N { {a_i}{a_j}{y_i}{y_j}K({x_i},{x_j}) - \sum\limits_{i = 1}^N { {a_i}} } } \]
参数\({b^\*}\)的计算公式变成了(但分量\(j\)的选取条件未变):
\[ {b^*} = {y_j} - \sum\limits_{i = 1}^N {a_i^*{y_i}K({x_i} \cdot {x_j})} \]
而分类决策函数也相应变了
\[ f(x) = sign(\sum\limits_{i=1}^N {a_i^*{y_i}K({x_i}, {x_j})} + {b^*}) \]
其余的公式都与上面的线性支持向量机相同。
其实在实际的应用中,并不需要找映射函数,只需要使用到核函数,而且核函数也不需要我们费什么劲去找,可以直接用一些常用的核函数,例如:多项式核函数,高斯核函数,字符串核函数等。
小结
前面简单介绍了支持向量机,支持向量机分为线性支持向量机和非线性支持向量机。非线性支持向量机是通过核函数将一个线性不可分的问题转变成为一个线性可分的问题。其实线性支持向量机可以视为一种使用了特殊核函数\(K({x_i},{x_j})=({x_i}\cdot{x_j})\)的非线性支持向量机。那么SVM的对偶问题可以统一表示为下面的公式。SVM的学习,就是求出下面问题的解。
\[ \begin{array}{l} \mathop {\min }\limits_a \qquad \frac{1}{2}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N { {a_i}{a_j}{y_i}{y_j}K({x_i},{x_j}) - \sum\limits_{i = 1}^N { {a_i}} } } \\ {\rm{s.t.}}\qquad\sum\limits_{i = 1}^N { {a_i}{y_i} = 0} \\ \qquad\qquad 0 \le {a_i} \le C, \qquad i = 1,2,\cdot\cdot\cdot,N \end{array} \]
选择一个 $ {a^*} $ 的正分量 $ 0 C $ , 计算(或者通过所有解求平均值):
\[ {b^*} = {y_j} - \sum\limits_{i = 1}^N {a_i^*{y_i}K({x_i} \cdot {x_j})} \]
决策函数为
\[ f(x) = sign(\sum\limits_{i=1}^N {a_i^*{y_i}K({x_i}, {x_j})} + {b^*}) \]
有了问题,如何利用计算机,解出这些数学公式的答案。换句话说,就是怎么通过计算机算出我们的svm模型的参数呢?方法就是序列最小最优化(sequential minimal optimization, SMO)算法。下一篇文章,我们就来讲解SMO。
相关工具
本文中的例子和图片都是用python制作的。可以参考github上相关的代码,有兴趣的同学可以讲代码拷贝过去,运行一下。
- blog_linear.py可用于生成这篇博文中线性支持向量机的图片
- blog_kernel.py生成非线性支持向量机的核技巧展示图片
- smo.py是smo算法的实现,下一篇文章将讲到。
图片使用了python的扩展库matplotlib。安装matplotlib方法如下:
我使用的是ubuntu 12.04, 最简单的安装方法
1 | sudo apt-get install python-matplotlib |
但不是最新的,要安装最新,按照下面的方法
在ubuntu下安装scipy-numpy-matplotlib-ipython
John Hunter (1968-2012)

On August 28 2012, John D. Hunter, the creator of matplotlib, died from complications arising from cancer treatment, after a brief but intense battle with this terrible illness. John is survived by his wife Miriam, his three daughters Rahel, Ava and Clara, his sisters Layne and Mary, and his mother Sarah.
If you have benefited from John’s many contributions, please say thanks in the way that would matter most to him. Please consider making a donation to the John Hunter Memorial Fund.
Thanks for creating such a great tool. May you rest in peace!