| 摘要: | 简单介绍了zookeeper的概要,主要是翻译了apache zookeeper overview的内容。 |
ZooKeeper 简介
ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。1
Zookeeper是Google的Chubby一个开源的实现,关于Chubby,可以google一下,有论文介绍的。zookeeper是高有效和可靠的协同工作系统。Zookeeper能够用来leader选举,配置信息维护等。在一个分布式的环境中,我们需要一个Master实例或存储一些配置信息,确保文件写入的一致性等。
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,包含一个简单的原语集,是Hadoop和Hbase的重要组件。目前提供Java和C的接口。
在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据.如果在创建znode时Flag设置为EPHEMERAL,那么当这个创建这个znode的节点和Zookeeper失去连接后,这个znode将不再存在在Zookeeper 里.Zookeeper使用Watcher察觉事件信息,当客户端接收到事件信息,比如连接超时,节点数据改变,子节点改变,可以调用相应的行为来处理数 据.Zookeeper的Wiki页面展示了如何使用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁,可撤销的共享锁,两阶段提交.
znodes与Unix文件系统路径相似相似,但是还是不同的,znode的中间节点是可以保存数据的,对应于文件系统,就即是文件又是目录。为了达到高吞吐的能力,znode在zookeeper中是放在内存中的。
ZooKeeper是以Fast Paxos算法为基础的,paxos算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos作了一些优化,通过选举产生一个leader,只有leader才能提交propose,具体算法可见Fast Paxos。因此,要想弄懂ZooKeeper首先得对Fast Paxos有所了解。
ZooKeeper的基本运转流程:
1、选举Leader。
2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的zxid。
5、集群中大多数的机器得到响应并follow选出的Leader。
ZooKeeper Overview
结构
zookeeper service本身就是一个分布式集群,这一点和chubby是一样的。一个典型的集群由5个节点组成,他们之间选举出一个leader。构成zookeeper service的server有个前提条件,就是这些server是相互能够感知的。所有的server都保存了一个zookeeper的数据和状态的一个镜像,而且为了获得高吞吐能力,这个镜像是存放在内存中的。这个镜像是通过事务日志和某一时刻全部数据的快照生成的。
Zookeeper的客户端连接到zookeeper的server上,客户端保持一个与server之间的TCP连接,并通过这个TCP链接发送请求,获取响应,获取watch事件,和发送心跳。如果连接断掉了,那么客户端将会自动连接到另外一个server。
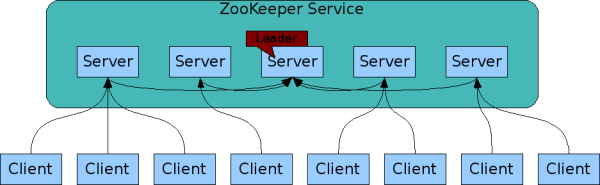
zookeeper的操作是有顺序的,zookeeper为每一个操作添加一个数字,通过这个数字可以体现出所有ZooKeeper transactions的顺序。后续的操作,可以通过这个种顺序去实现更上层的应用,例如同步操作。
zookeeper的数据模型,类似文件系统,通过定一个了Hierarchical Namespace的概念,一个name就是路径,每一个节点znode都是通过一个路径来定义的。ZooKeeper’s Hierarchical Namespace的一个示例:
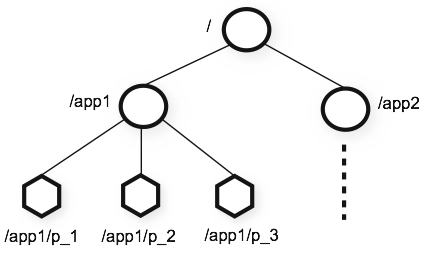
节点和临时节点
在zookeeper中,每个节点(znode)可以包含数据信息。就像传统的文件系统中,允许既可以是文件,又可以是目录。 zookeeper的设计目的就是存放同步信息:状态信息,配置,位置信息等等。所以每个节点存放的数据都是非常小的。具体实现是,可能是一个路径对应DB中的一项数据,例如chubby就是使用Berkeley DB来保存Node的信息。
znode实际上包含的是一个有状态的数据,它包含了数据变更的版本号,ACL(Access Control List)变更的版本号,时间戳。每次数据变更时,version就是增加。例如,每次客户端查找收到一个node的数据,同时还会收到这个数据的版本号。
znode的数据操作是原子性的,读操作将会获取znode的所有数据,写操作操作将会覆盖所有的数据。而且没有节点的都通过ACL来限制谁可以操作。
zookeeper还支持临时节点,当创建临时节点的session结束时,临时节点也会被zookeeper删除。例如,可以利用这种机制监控系统中有哪些client不存在了。
Conditional updates and watches
zookeeper支持watch事件,客户端可以向一个znode注册一个watch事件。当这个节点发生改变时,这个watch事件将被激活,同时被注销。当一个watch事件触发是,zookeeper将会给客户端发送一个通知消息。如果客户端和zookeeper servers直接的连接断掉了,那么客户端会收到本地的一条连接断掉的消息。
保证(Guarantees)
zookeeper非常简单快速,它的设计目的,是在它之上可以构造复杂的服务,例如同步。那么zookeeper就应该向上提供一些保证:
- 序列一致性:从一个客户端发送的一系列更新操作,讲会按照发送顺序执行。
- 原子性:更新要么成功,要么失败,没有中间状态,不会一部分成功,一部分失败。
- 数据一致性:在客户端看来,所有的服务和数据都是一样的,无论它连接到哪个服务器。
- 可靠性:一旦更新成功,那么这种更新将是永久性的,直到下次更新。
- 时效性:在client看来,一个更新操作后,zookeeper将在一个固定的时间内,更新所有的zookeeper server。
Simple API
ZooKeeper提供了非常简单的编程接口,它仅仅支持以下操作:
- create 创建一个znode节点
- delete 删除一个znode节点
- exists 测试一个znode节点是否存在
- get data 读取一个znode节点的数据
- set data 写一个znode节点的数据
- get children 写一个znode节点的children列表
- sync 等待znode节点的数据,在zookeeper server中同步
Implementations
下图展示了ZK的模块图,这个模块图是非常顶层和概要的。除了request processor不相同以外,其余的所有的ZK service中的server都有每个模块的一模一样的副本。
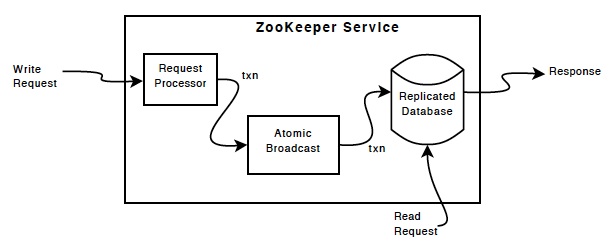
replicated database 存放了所有的数据,并且存放在内存中。所有的更新就会以日志的形式记录到磁盘中,以便可以用于灾后重建,所有的写操作,都先序列化到磁盘中,然后再写到内存中的database中。
每个zk server为zk clients服务,zk客户端连接到一台zk服务器上,而且只能连接到一台,并向服务器发送请求。所有的读请求,都有zk server从本地的replica database中直接获取数据。所有写请求,或是改变服务状态的请求,zk会基于一个agreement protocol进行处理。
agreement protocol的一部分,就是所有的来自客户端的写请求,就讲被转发到一个特定的zk server上(这个zk server被称为leader,其余的zk server称为followers)这时,所有的followers就会接收到来自leader的一个“提议消息”,并且同意这个消息。
替换leader或同步followers的工作是有messaging layer完成的。
Performance
ZooKeeper的一个目标就是高性能。由雅虎研究院开发zookeeper的小组所做的测试实验证明了zk的高性能。下图是他们的实验结果:
ZooKeeper Throughput as the Read-Write Ratio Varies
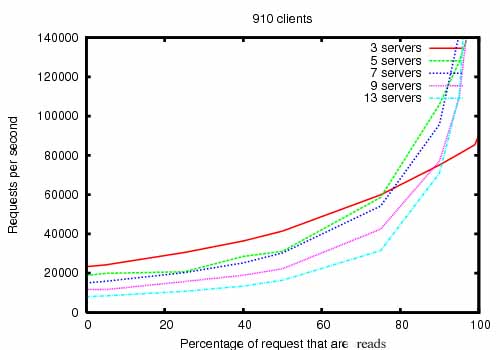
当读请求远远高于写请求时zk的性能会更好。因为写请求需要同步所有的zk server。通常情况下当读写比例为10:1时,性能就可以达到一个比较好的效果了。
Reliability
在zookeeper的介绍页面,还有关于failure的一个实验。实验表明zk在存在failure的情况下,依然可以保证比较高的吞吐能力。但更重要的是,leader选举算法可以保证系统能够很快从错误中恢复正常。在实验中观察,选举出新的leader的耗时少于200毫秒。当follower恢复正常后,zk的吞吐能力马上就上去了。
连接库
zookeeper可以通过多种方式连接,正式发布包里面包含了java和C种方式进行连接(就是客户端),C连接方式,有个库,单线程的zookeeper_st和多线程的zookeeper_mt。 zookeeper_st放弃了事件循环,可在事件驱动的应用程序中使用。而zookeeper_mt更加易用,与Java API类似,创建一个网络IO线程和一个事件分发线程,用来维护连接和执行回调。 在具体使用上,zookeeper_st仅提供了异步API与回调,用以集成至应用程序的事件循环。它只是为了支持pthread库不可用或不稳定的平台而存在,例如FreeBSD 4.x。除此以外的其他情况,应使用提供同步与异步两种API的zookeeper_mt。[^1]
当然还有其它语言非正式发布的连接库:ZKClientBindings。
zk集群
配置zookeeper集群其实也是比较简单地的。配置方法就是standalone mode的配置文件基础上添加几个配置项,下面是一个示例:
1 2 3 4 5 6 7 8 | |
单机版中包含了tickTime,dataDir,clientPort三个配置项。2
- tickTime 是zk的时钟周期,单位是毫秒。Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime时间就会发送一个心跳。tickTime以毫秒为单位。
- dataDir 保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
- clientPort 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
在集群配置中多出来了,initLimit,syncLimit,server.x配置项。
- initLimit 集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
- syncLimit 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
- server.X 集群信息(服务器编号,服务器地址,Leader Followers通信端口,选举端口)
这个配置项的书写格式比较特殊,规则如下:
server.N=YYY:A:B
其中N表示服务器编号,YYY表示服务器的IP地址,A为leader followers(LF)通信端口,表示该服务器与集群中的leader交换的信息的端口。B为选举端口,表示选举新leader时服务器间相互通信的端口(当leader挂掉时,其余服务器会相互通信,选择出新的leader),连接方式也是tcp。一般来说,集群中每个服务器的A端口都是一样,每个服务器的B端口也是一样。但是当所采用的为伪集群时(所有的zk server在一台服务器上),IP地址都一样,只能时A端口和B端口不一样。
当一台zk服务器启动时,它通过查看myid文件,可以知道自己是这些配置中的哪一台服务器。myid文件包含了服务器的数字编号。
试用
先装一个zookeeper Standalone来试试。安装和配置还是十分简单的,参考ZooKeeper Getting Started Guide上面讲到地,进行就可以了。配置完后,就可以启动zookeeper了,启动命令可以参考前面的Guide。
zooker启动后可以使用客户端连接zookeeper service了,有两种客户端使用,一是java版,另外一个是c版的。可以先使用java版的练习一下。
实际上启动了java的client后,看到的是一个类是shell的交互式界面了,通过这个shell可以做很多事情,通过命令help来查看。
[zkshell: 0] help
ZooKeeper host:port cmd args
get path [watch]
ls path [watch]
set path data [version]
delquota [-n|-b] path
quit
printwatches on|off
createpath data acl
stat path [watch]
listquota path
history
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
setquota -n|-b val path
ZooKeeper Getting Started Guide还举一个通过zkshell进行znode的创建、查看、更新、删除等操作。
总结
上面简单介绍了zookeeper,包括zookeeper的一些概念和框架等,绝大部分是直接翻译了zookeeper Overview。下一篇文章就讲讲ZooKeeper Programmer’s Guide,当然重点是C binding。
在网上查找zookeeper的资料时,找到了几篇不错的文章3456,大家可以一读。另外还找到一篇介绍google的chubby的不错的blog——Google利器之Chubby,这个blog还写了关于google的分布式重用的5篇论文的文章,第一篇是Google利器之Google Cluster,如果大家有兴趣可以顺着读下去看一看。